3 février 2023
Nous sommes quatre étudiants ingénieurs en dernière année à Polytech Nice Sophia, spécialisés en Architecture Logicielle :
Le sujet d’étude de la qualité logicielle dans les notebooks Jupyter nous a intéressé de part des expériences personnelles passées avec ce type de projet.
Plusieurs points nous ont poussé à nous poser des questions sur la qualité du code des notebooks Jupyter. Dans de précédents projets collaboratifs, les notebooks Jupyter ont dû être utilisés. Lors de son stage de 4ème année, un des membres de l’équipe a dû convertir un notebook Jupyter d’intelligence artificielle en code Python dans le but d’une démonstration destinée à un client. Il a donc eu à récupérer tous les bouts de code du notebook utilisé et les assembler en un script Python tout en le rendant lisible, en optimisant les imports et en commentant du code. Lors de cette expérience, il a été confronté à un code qui n’avait pas été écrit par un développeur mais un data scientist. Les noms des variables et des fonctions n’étaient pas explicites, de plus il manquait des commentaires essentiels à la compréhension de chaque partie du programme. N’ayant pas participé à la création du notebook, il a donc eu beaucoup de difficultés à le comprendre, le reprendre et le convertir en quelque chose d’acceptable pour un développeur.
Ce sujet est intéressant à aborder car il nous permettrait de savoir sur quels critères de qualité logicielle mesurer la qualité du code d’un notebook Jupyter. Ce sujet n’étant que peu voire pas abordé la question reste assez nébuleuse. On pourrait ainsi savoir quels sont les forces et faiblesses des codes des notebooks.
Pour que notre étude ne devienne pas trop complexe, nous ne considèrerons que des notebooks reproductibles dont le code build.
Nous allons nous demander dans cette étude comment mesure-t-on la qualité d’un notebook ? Nous en avons déduit deux sous-questions : Afin de compléter notre étude et pouvoir mieux répondre à cette question nous allons chercher à répondre aux deux sous-questions suivantes :
Pour notre recherche, nous allons nous baser sur les quatre articles suivants :
Eliciting Best Practices for Collaboration with Computational Notebooks
Auteurs :
Date de publication : Avril 2022
Ce qui nous est montré par cet article : Dans cet article, une revue de littérature a été effectuée afin de construire un catalogue de 17 meilleures pratiques pour la collaboration avec les notebooks. Ensuite, sont évalués qualitativement et quantitativement la mesure dans laquelle les experts en sciences des données les connaissent et les respectent. Dans l’ensemble, cet article permet de constater que les scientifiques spécialistes des données connaissent les meilleures pratiques identifiées et ont tendance à les adopter dans leur routine de travail quotidienne. Néanmoins, certains d’entre eux ont des opinions contradictoires sur des recommandations spécifiques, en raison de facteurs contextuels variables. En outre, nous avons constaté que les meilleures pratiques les plus négligées ont trait à la modularisation du code, aux tests de code et au respect des normes de codage. Cela met en évidence ce qui semblerait être une tension entre la vitesse et la qualité. Pour résoudre cette tension, les plateformes de notebooks devraient mettre en œuvre des fonctionnalités natives qui facilitent l’adoption des pratiques de collaboration susmentionnées. En disposant de cadres de test et de linting intégrés et spécifiques aux blocs-notes, ainsi que de fonctions de refactoring et de modularisation du code des blocs-notes, nous pouvons nous attendre à ce que les blocs-notes de données soient plus faciles à utiliser, nous pouvons espérer que les scientifiques des données écrivent des notebooks de haute qualité sans compromettre sur la rapidité d’exécution.
What’s Wrong with Computational Notebooks? Pain Points, Needs, and Design Opportunities
Auteurs :
Date de publication : 25 au 30 avril 2020
Ce qui nous est montré par cet article : Dans cet article, une étude à méthode mixte a été menée avec des scientifiques spécialisés dans les données en utilisant des observations sur le terrain, des entretiens et une enquête. Lors des études sur le terrain et des entretiens, les spécialistes des données ont signalé diverses difficultés lorsqu’ils travaillaient avec des ordinateurs portables et synthétisé ces difficultés dans une classification des points posant problème dans le code. Nous avons validé les activités difficiles qui contribuent à ces points posant problème dans le code par le biais d’une enquête et nous avons constaté que le soutien de toutes les activités étaient au moins modérément importantes pour les scientifiques spécialistes des données, et que quatre activités - la refonte du code, le déploiement en production, la gestion et l’utilisation de l’historique, et l’exécution de tâches de longue durée - étaient à la fois difficiles et importantes, ce qui en fait des activités à fort impact. Nos résultats suggèrent plusieurs possibilités de conception pour les chercheurs et les développeurs de notebooks. La résolution de ces problèmes peut améliorer considérablement l’utilité, la productivité et l’expérience utilisateur des scientifiques qui travaillent avec des notebooks.
Ten simple rules for writing and sharing computational analyses in Jupyter Notebook.
Auteurs :
Date de publication : 25 juillet 2019
Ce qui nous est montré par cet article : Des analyses robustes et reproductibles sont au cœur de la science, et plusieurs articles ont déjà fourni d’excellents conseils généraux sur la manière de réaliser et de documenter la science informatique. Cependant, l’avènement des notebooks informatiques présente de nouvelles opportunités et de nouveaux défis, facilitant la documentation précise de flux de travail complexes tout en la compliquant par l’interactivité. Nous présentons 10 règles simples pour écrire et partager des analyses dans des carnets Jupyter, en nous concentrant sur l’annotation de l’analyse, l’organisation du code, et la facilité d’accès et de réutilisation. Informés par notre expérience, nous espérons qu’ils contribueront à l’écosystème des individus, des laboratoires, des éditeurs et des organisations qui utilisent les notebooks pour performer et partager leurs recherches informatiques.
Managing Messes in Computational Notebooks
Auteurs :
Date de publication : 4 au 9 mai 2019
Ce qui nous est montré par cet article : L’étude qualitative menée de scientifiques a confirmé que le nettoyage des notebooks consiste principalement à supprimer le code d’analyse indésirable et les résultats indésirables. La tâche de nettoyage peut également comporter des étapes secondaires telles que l’amélioration de la qualité du code, la rédaction de la documentation, l’adaptation de la présentation des résultats pour un nouveau public cible, ou la création de scripts. Les participants considèrent que la tâche principale de nettoyage est un travail de bureau et qu’elle est sujette à des erreurs. Ils ont donc réagi positivement aux outils de collecte de code qui produisent automatiquement le code minimal nécessaire pour reproduire un ensemble choisi de résultats d’analyse, en utilisant une nouvelle application de découpage de programme. Les analystes ont principalement utilisé la collecte de code en dernière action pour partager leur travail, mais y ont aussi trouvé des utilisations inattendues comme la génération de matériel de référence, la création de branches plus légères dans leur code, et créer des résumés pour des publics multiples.
Les outils que nous envisageons d’utiliser pour effectuer notre étude sont :
Les codes que nous analyserons pour notre étude seront des projets de différentes tailles et auteurs proposées sur GitHub classés par nombre de visites avec pour choix un sujet commun : la réalité augmentée. Un script de récupération automatisé de projets de type notebook Jupyter (avec extension .ipynb) sera utilisé pour avoir une diversité de projets. Nous récupérons un fichier par page de projets publics GitHub. Ils seront ensuite transformés en code Python de qualité mesurable grâce aux outils cités dans la partie précédente par ce même script. Ce choix a été fait de par le fait que la majorité des notebooks Jupyter sont codés dans ce même langage et que cela n’entrainera donc pas de transformation du code. A ces projets récupérés, nous ajouterons des projets de réalité augmentée effectués en cours à Polytech Nice-Sophia lors de nos études.
Nous avons émis plusieurs hypothèses au début de notre étude :
Au vu du temps imparti pour mener cette étude, nous sommes bien sûr obligés de faire des expériences avec certaines limitations au niveau de l’analyse des résultats.
Nous ne connaissons pas précisément les critères utilisés par les outils que nous utilisons. Nous ne maitrisons par exemple pas la pondération des différentes erreurs dans PyLint et l’analyse faite par SonarQube s’oriente plus sur l’analyse de la programmation orientée objet ou POO. Nous ferons tout ce qui est possible pour essayer d’obtenir des résultats objectifs mais l’idéal serait bien sûr de définir beaucoup plus précisément quels sont nos critères que qualité dans le cas spécifique des notebooks Jupyter.
De plus, nous avons décidé de récupérer un notebook par page de résultat GitHub ce qui est bien mais reste peut-être une quantité un peu faible pour représenter correctement la qualité moyenne des notebooks. Nous aurions pu prendre plusieurs notebooks par page ou encore aller chercher des notebooks sur d’autres plateformes et notamment Kaggle pour que notre jeu de donnée sont complètement représentatif de la moyenne des notebooks qui sont écrits.
Préalablement à la mise en place de nos expériences, nous avons eu à récupérer un ensemble de notebooks Jupyter. Le code des fichiers .ipynb récupérés est par la suite transformé en un unique code, somme de toutes les cellules du notebook, via passage dans notre script. L’extension de ce fichier est celle du langage de programmation utilisé dans le notebook. Le script filtre ensuite les fichiers obtenus afin de ne garder que ceux dont l’extension est celle des codes Python.
La démarche que nous avons prévu pour l’analyse de ce sujet se découpe en trois étapes :
SonarQube basera ses analyses du code sur sept critères :
Il donnera à chacun de ces critères numériques une note allant de A à F permettant de juger de leur qualité.
Cette première démarche terminée, nous avons décidé d’utiliser CodeClimate pour analyser nos notebooks. CodeClimate permet d’analyser des projets Python et de leur attribuer une note de qualité décrémentale en fonction du nombre d’erreurs, d’exceptions et de non-respect de critères de qualité du code tels que les emplacements de déclaration d’imports ou des redéfinitions de variables. Malheureusement, l’application de CodeClimate à nos notebooks de référence cause des erreurs, nous sommes donc à la recherche d’autres solutions d’analyse des projets notebook Jupyter et de la qualité du code Python.
Après des recherches plus approfondies, CodeClimate propose l’équivalent d’un PyLint Python, c’est-à-dire un outil qui analyse votre code sans l’exécuter. Il vérifie les erreurs, applique une norme de codage, recherche les odeurs de code et peut faire des suggestions sur la façon dont le code pourrait être remanié. Pylint peut déduire les valeurs réelles de votre code en utilisant sa représentation interne du code. Une première étape serait l’utilisation du plugin PyLint simple sur nos notebooks de référence pour analyse de leur qualité, une note entre 0 et 10 leur serait alors attribuée. Après une première utilisation de PyLint nous nous sommes aperçus que ses configurations de base ne sont pas forcément pertinentes dans le cas des notebooks. Nous avons donc écrit un script de configuration de PyLint afin d’exclure de ses vérification la liste d’exceptions suivante :
Ces erreurs sont récurrentes mais en réalité peu pertinentes dans le cas des notebooks.
Les autres outils envisagés n’ont pas été utilisés car ils reprenaient des métriques déjà mesurées au cours de nos autres expériences ou se concentraient au final trop sur l’aspect sécuritaire du code qui est sûrement celui-ci qui a le moins d’intérêt pour nos scientifiques spécialistes des données.
Comme expliqué précédemment, SonarQube nous permet de donner une note de qualité aux projets évalués. Ci-dessous, des résultats observés sur les projets proposés par Microsoft :
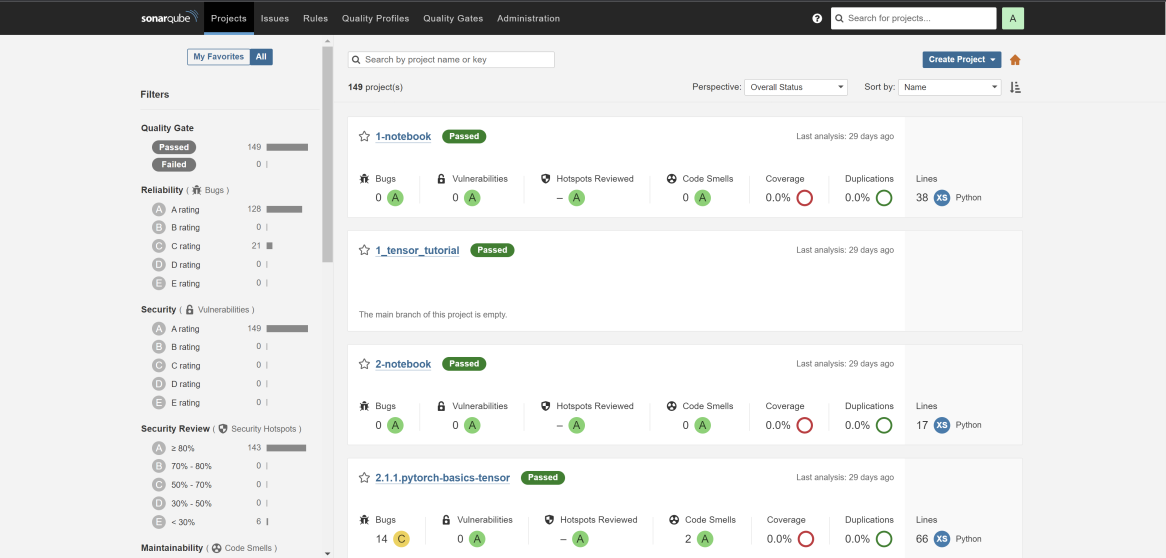
Comme nous le pressentions, les projets Microsoft reçoivent de bonnes notes lors de leur analyse par SonarQube ce qui viendrait appuyer notre hypothèse de départ selon laquelle les projets Microsoft sont de bonne qualité. Tous les projets ne sont pas classés comme étant de bonne qualité par SonarQube ce qui démontre une réelle application des critères de classement de cet outil, on peut ainsi voir ci-dessous que parmi les projets que nous avons sélectionnés, les scores les plus bas obtenus sont des C soit une qualité moyenne.
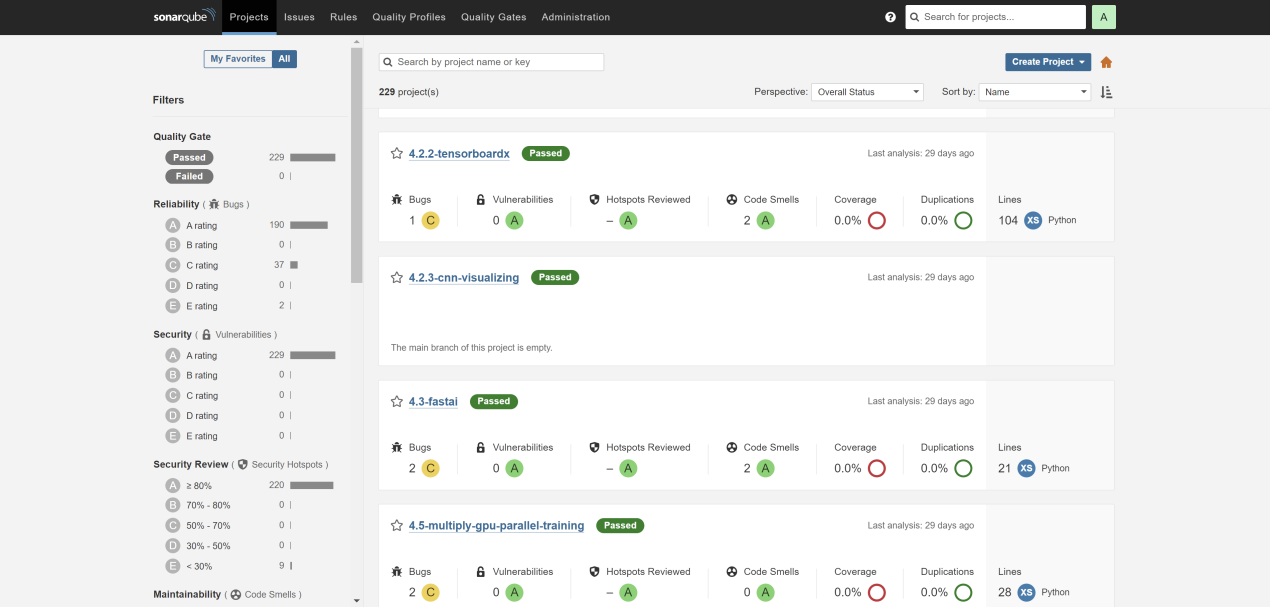
Nous pouvons toutefois noter plusieurs choses :
Comme dans tout code informatique nous nous attendons à trouver des vulnérabilités dans le code, d’autant plus que certains des projets étudiés sont des labs écrits par des étudiants, il est donc étonnant de noter que l’ensemble de nos projets obtiennent la note maximale pour ce critère car ne possèdent aucune vulnérabilité.
Comme formulé en hypothèse, le taux de couverture de tests retrouvé est nul. Nous pouvons donc à la fois valider notre hypothèse de départ et écarter ce critère des métriques de qualimétrie de nos notebooks. Ajoutons à cela que les notebooks sont des types de projets généralement utilisés par des scientifiques spécialistes de données et que les tests de code ne sont pas la priorité ni le but de ces projets.
Voici le résultat à une métrique le plus étonnant, le taux de duplication du code. Il est connu que les notebooks contiennent des lignes dupliquées, le fait de n’en trouver aucune lors de l’analyse par SonarQube parait donc suspect car l’on devrait au moins tomber sur des déclarations multiples de mêmes variables et ainsi des duplications de code. On peut donc penser que cette
Pour cette seconde expérience nous avons voulu mesurer la qualité du code de nos notebooks à l’aide de l’outil CodeClimate afin d’avoir des résultats mais aussi des métriques complémentaires à ce que nous avions pu trouver avec l’outil SonarQube. Malheureusement, de l’intégration à notre script d’évaluation de la qualité de l’outil CodeClimate n’a résulté que l’erreur suivante ne nous permettant donc par d’analyser nos projets.

En étudiant de plus près CodeClimate, nous avons pu nous rendre compte que pour une analyse de code Python, l’outil s’appuyait en fait sur le linter PyLint pour évaluer la qualité de code. Nous avons donc tenté d’utiliser PyLint sur nos projets mais les résultats obtenus étaient peu concluants. En effet, de nombreux codes certes de faible qualité mais compilant malgré tout obtenaient la note de 0 sur 10. Nous nous sommes alors posé la question des critères d’évaluations appliqués par PyLint et de leur pertinence dans le cas de notebooks Jupyter. Ainsi, nous avons pu écarter la liste de critères de notation suivants :
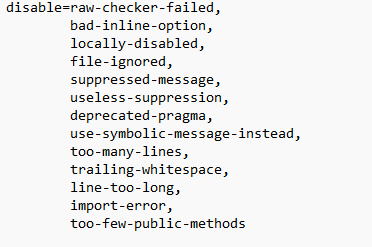
Les sept premiers critères ont été placés directement par Pylint et il semble cohérent de les laisser, d’autant plus quand on regarde en détail leur signification. Si on regarde ensuite les critères que nous avons retirés nous-mêmes, on trouve plusieurs critères que nous ne jugeons pas révélateurs de la qualité d’un fichier Python en général tels que comme trailing-whitespace ou encore too-many-lines. Nous avons ensuite retiré certains critères qui ne correspondent pas au cas des notebooks Jupyter comme too-few-public-methods et too-many-lines. Enfin, nous avons retiré import-error pour des raisons pratiques car nous ne pouvons pas installer tous les packages Python avant chaque analyse dans le cadre de plusieurs centaines de fichiers. Il semble de toute manière peu probable que des mauvais imports soient faits puisque cela empêcherait le code de s’exécuter.
Cela a ainsi, à titre d’exemple, fait évoluer la note du projet NLP_C1_W1_lecture_nb_01 de 3.60 à 8.27 et cela se confirme globalement sur tous nos notebooks même si on retrouve toujours de très mauvaises notes. Cela nous amène à penser que l’évaluation s’affine et devient un peu plus juste.
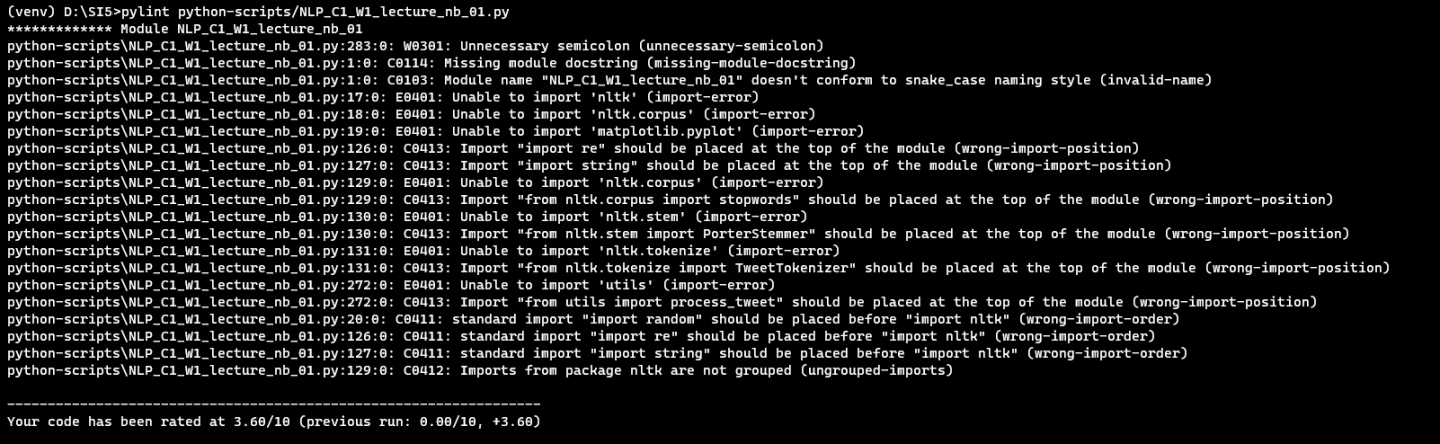
A la note suivante après application des configurations à désactiver.
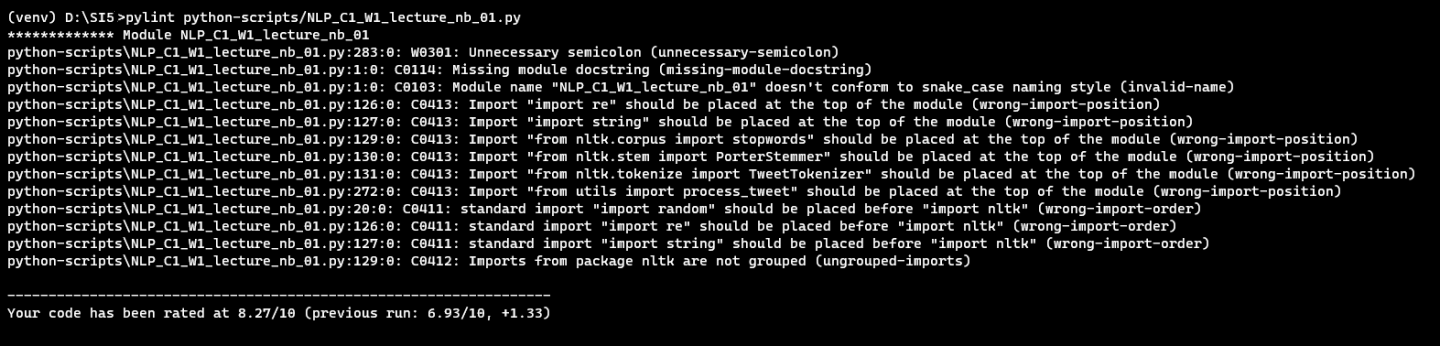
Une fois nos critères de notations précisés, il nous est donc resté à analyser les erreurs les plus courantes dans les notebooks analysés afin de déterminer de potentielles métriques de qualité de notre code. Ainsi, après analyse de 649 notebooks, les vingt erreurs les plus rencontrées lors de notre analyse étaient les suivantes :
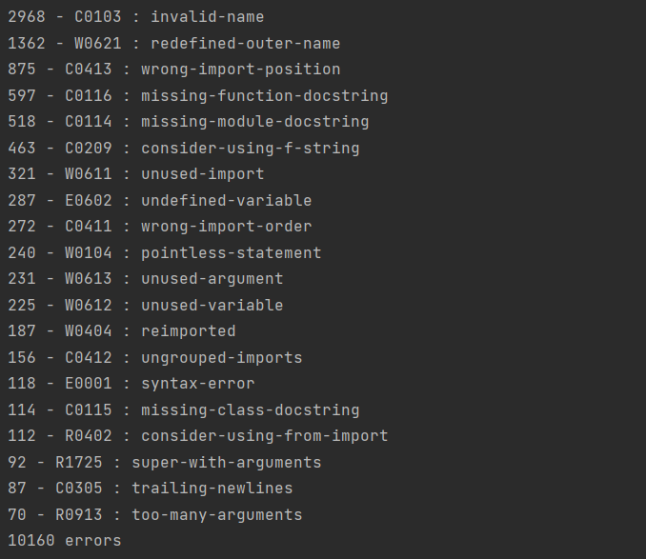
On remarque que les deux erreurs les plus récurrentes concernent un problème de nommage de variable. C’est une erreur qui sera probablement commise par des personne peu adeptes des principes de qualité. Ce problème de nommage n’est pas une erreur importante car il ne va pas empêcher la compréhension ni l’exécution d’un notebook. En revanche, si le problème est étendu à tout le fichier, on pourrait perdre le lecteur dans la compréhension du notebook. Cette erreur est donc mineure et n’impactera pas énormément la note finale.
Cependant, les erreurs suivantes concernent des variables inutilisées, des erreurs de syntaxe ou encore un surplus d’arguments pour une méthode. Ces erreurs sont plus lourdes et impacteront grandement la note car elles peuvent rendre un notebook inutilisable ou non-reproductible. On se rend assez vite compte que plus une erreur est impactante, moins elle est commise. C’est un résultat cohérent dans la mesure où une erreur qui rendrait un notebook non-reproductible est plus connue qu’une simple erreur d’inattention et donc plus corrigée.
On a maintenant les preuves que PyLint est un indicateur de qualité pertinent dans l’évaluation d’un notebook. Certaines erreurs comme le nommage des variables ou la documentation des fonctions manquante pourraient former une première métrique de lisibilité. D’autres erreurs comme le nombre trop élevé d’arguments dans une fonction ou une mauvaise syntaxe sont des erreurs plus lourdes et pourraient constituer des métriques d’erreurs d’exécution. On pourrait alors évaluer la qualité d’un notebook sur la base de sa lisibilité et de son exécution.
Nous avons ensuite voulu visualiser la répartition des notes des différents notebooks dans le but de vérifier si les nombreuses erreurs repérées influaient sur la note desdits notebooks. Nous obtenons la figure suivante représentant le nombre de notebook par note (arrondie à 1 chiffre après la virgule) :
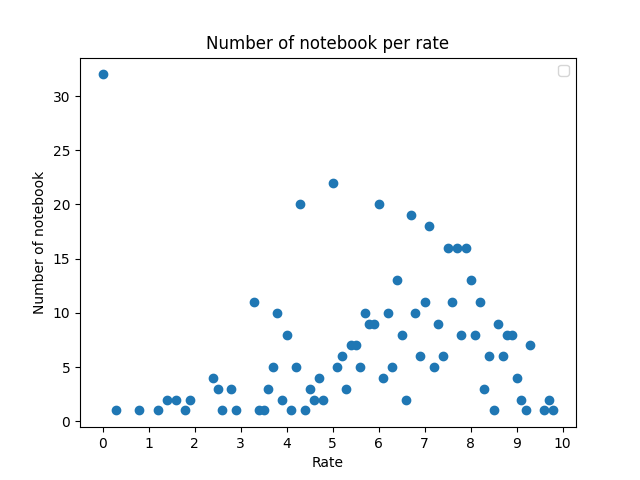
La répartition des notes sur notre schéma, même si elle est moins disparate que celle observée avec SonarQube, semble classer les précédents bons projets comme de bons projets. Nous avons toutefois une bien plus grande répartition des projets moyens qu’auparavant. On peut également remarquer une légère courbe de Gauss décalée vers la droite, on peut en déduire que les projets semblent tendre vers une qualité acceptable.
Nous avons également voulu rassembler les projets par tranche de note afin de mieux visualiser la répartition des notes obtenues. Nous avons établi 4 sections :
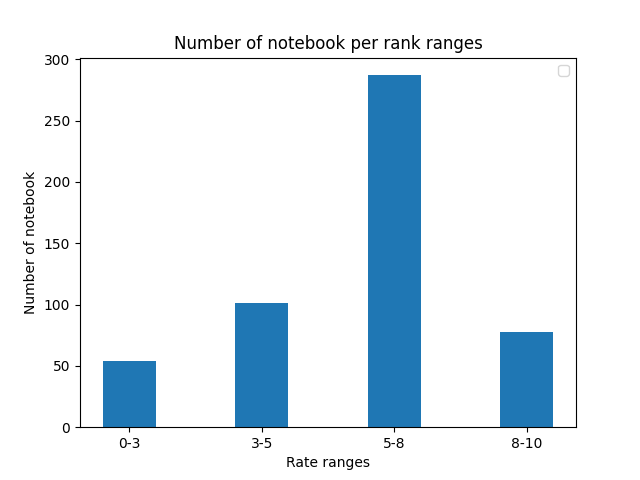
On retrouve la courbe de Gauss décalée vers la droite du précédent schéma qui semblent indiquer que la majorité des notebooks analysés se trouvent dans la tranche haute des notebooks moyens.
Ces deux graphiques utilisant la note générée par PyLint montrent que la majorité des notebooks sont de qualité moyenne. Cela semble indiquer que PyLint est un bon outil pour mesurer la qualité d’un notebook.
Pour terminer, nous avons voulu vérifier notre hypothèse de bonne qualité des notebooks Microsoft avec Pylint. Voici les résultats obtenus pour les différents fichiers Python générés à partir des notebooks Microsoft :


Nous avons ainsi pu observer que nous obtenions pour ces notebooks deux notes plutôt moyennes et une bonne note. Ces résultats remettent en question notre hypothèse de départ de bonne qualité des notebooks Microsoft. Il semblerait que les notebooks Microsoft sont en réalité dans la moyenne haute des notebooks analysés mais ne sont pas les meilleurs notebooks que nous avons trouvés.
Pour définir ce qui rend une métrique pertinente, il faut bien remettre en place le contexte dans lequel nous nous trouvons. Les notebooks Jupyter ne sont pas des logiciels de développement et n’auront jamais à être déployés pour être mis en production. Il s’agit ici de projets conçus pour pouvoir être lus comme des articles scientifiques avec du code servant à la démonstration de concepts et d’hypothèse qui sera interfacé par des écrits. Un notebook étant utilisé dans un but de démonstration de recherche, il devra ainsi être facilement compréhensible que ce soit au niveau du code comme au niveau des explications textuelles qui y sont liées. Le code proposé dans les notebooks servant à la démonstration, il ne sera pas testé, il n’est donc pas intéressant d’en analyser des métriques telles que la couverture de tests.
Connaissant le contexte de notre étude, il est pertinent qu’une partie de nos notebooks soit axée sur la lisibilité de ces derniers que ce soit d’un point de vue du code comme de celui des explications. Ainsi des métriques relatives à la complexité du code avec des fonctions trop longues, composées de trop de boucles et conditions ou encore de trop d’arguments pourrait être pertinent dans notre cas.
Il est à noter, les notebooks que nous étudions sont des notebooks reproductibles qui s’exécutent sans erreur fatale du code pour que tous les codes de notre jeu de données puissent tous être soumis aux mêmes métriques, nous n’avons ainsi pas de métriques liées à un seul code.
Les métriques proposées par les outils d’analyse mais n’impactant pas la compréhension des lecteurs, elles, pourront être laissées de côté comme dans le cas d’espaces en fin de ligne non visibles à la lecture ou un trop grand nombre de lignes dans notre notebook.
Enfin, certaines des métriques classiques d’évaluation classiques de la qualité du code sont jugées comme pertinentes car elles concernent tout code peu importe le langage dans lequel il est rédigé comme par exemple les métriques de détection de bugs ou d’erreurs dans code.
Pour terminer, certaines métriques jugées préalablement comme pertinentes pourront être abandonnées après analyse des résultats qu’elles fourniront au cours des expériences de l’étude.
Avec l’analyse de qualité des codes Python de notre jeu de données par l’outil Pylint, nous avons pu faire ressortir plusieurs critères d’évaluation du code relatifs à la lisibilité de ce dernier. Ce critère nous parait être l’un des plus évidents et pertinents à mettre en avant de par la nature même des notebooks. En effet, ces fichiers bien que comportant du code sont avant tout des feuilles de route permettant de suivre une démarche scientifique et les analyses des résultats qu’elle obtient. Ainsi, si un notebook n’est pas lisible il perd grandement de son intérêt premier. Cette lisibilité des notebooks peut se faire à travers divers critères tels que le nom des variables utilisées ou le manque de documentation par exemple.
Pour ce qui est de la qualité du code des notebooks eux-mêmes, les métriques suivantes ont été jugées comme intéressantes à utiliser. Les premières métriques intéressantes sont donc celles qui nous permettent de déterminer la lisibilité d’un notebook. Pour cela nous pouvons détecter les erreurs dans les noms de variable, les variables qui en cachent une autre ou encore, si la documentation est présente sur chacune des fonctions. Ces différentes métrique permettent de rapidement déterminer si le notebook peut être amélioré d’un point de vue de lisibilité. Les secondes métriques intéressantes sont celles qui remettent en cause la réutilisabilité d’un notebook. En effet, les notebooks vont parfois comporter des erreurs les empêchant de pouvoir se lancer. Certaines de ces erreurs peuvent être récupérées, notamment via PyLint. Ces métriques sont les syntax-error, les pointless-statements, undefined-variable. Toutes ces erreurs impactent directement la qualité d’un notebook car la qualité n’est pas nécessairement existante du point de vue de lisibilité, mais elle l’est aussi du point de vue fonctionnel.
D’autres métriques permettant de déterminer la qualité d’un notebook peuvent aussi avoir leur importance. Notamment les bugs à l’aide de l’outil SonarQube. Cependant, l’outil nous donne aussi des métriques inutiles dans notre cas. En effet, un notebook ne possède pas de tests et ne sera pas déployé, les métriques habituelles de sécurité ou de couverture de tests peuvent être totalement ignorées.
Il pourrait être intéressant d’analyser la qualité de codes Python avec celle de nos notebooks Jupyter pour voir quelles métriques sont les plus influencées par le passage d’un type de projet à l’autre. De cette manière, on pourrait alors voir les gains et les pertes de qualité constatés.
Au niveau des outils de développement, nous avons fait un script python nommé main.py qui nous permet de gérer massivement toutes les étapes de notre analyse. Le main nous permet de commenter/décommenter les méthodes que nous souhaitons utiliser en modifiant les paramètres des méthodes. Il faut absolument exécuter ce script depuis le dossier dans lequel il est place sans quoi cela ne fonctionnera pas.
Pour ce qui est des outils d’évaluation des métriques, nous avons dans un premier temps utilisé l’outil SonarQube. Nous avons deux containers pour deux instances. Il est possible de les lancer en faisant la commande docker-compose up. Nous avons mis en place des volumes qui permettent de conserver les analyses dans le temps. Les fichiers sont analysés en masse grâce au script Python.
Au niveau CodeClimate, nous avons utiliser leurs outils de ligne de commande présent sur GitHub pour analyse nos fichiers python avec la commande codeclimate analyze path_to_file. Cela est également fait de manière automatique dans notre script.
Dans le cas de PyLint, nous utilisons simplement la commande pylint path_to_file mais cela est à nouveau fait de manière automatisée dans notre script.
Pour finir, nous avons un second script parse_pylint_results.py qui nous a permis de générer les graphiques présentés ci-dessus.
Articles étudiés pour une meilleure compréhension des notebooks et du contexte dans lequel ils s’inscrivent pour une utilisation par les scientifiques spécialistes des données :
Eliciting Best Practices for Collaboration with Computational Notebooks
What’s Wrong with Computational Notebooks? Pain Points, Needs, and Design Opportunities
Ten simple rules for writing and sharing computational analyses in Jupyter Notebook.
![]()
